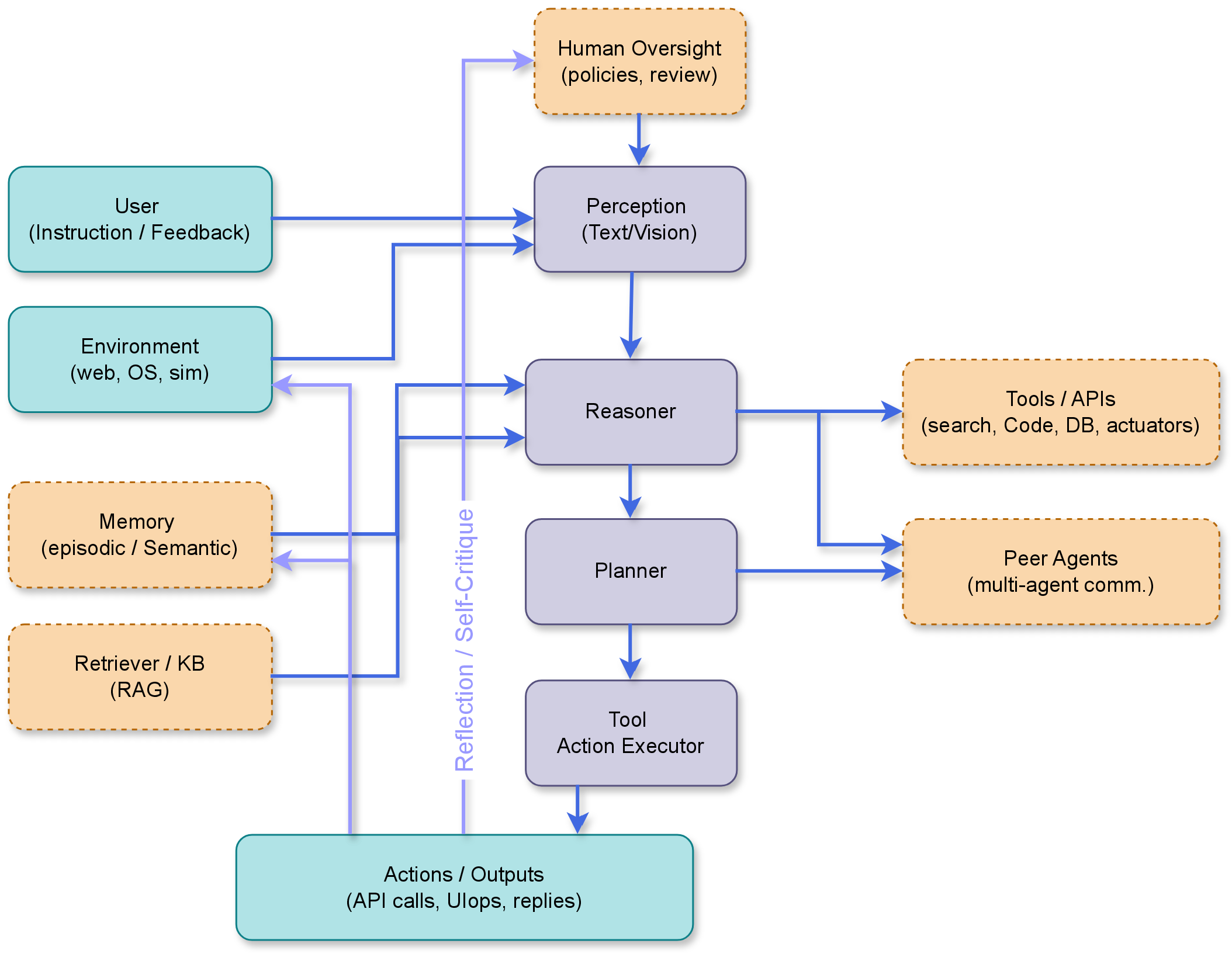
Agentic Pipeline Overview
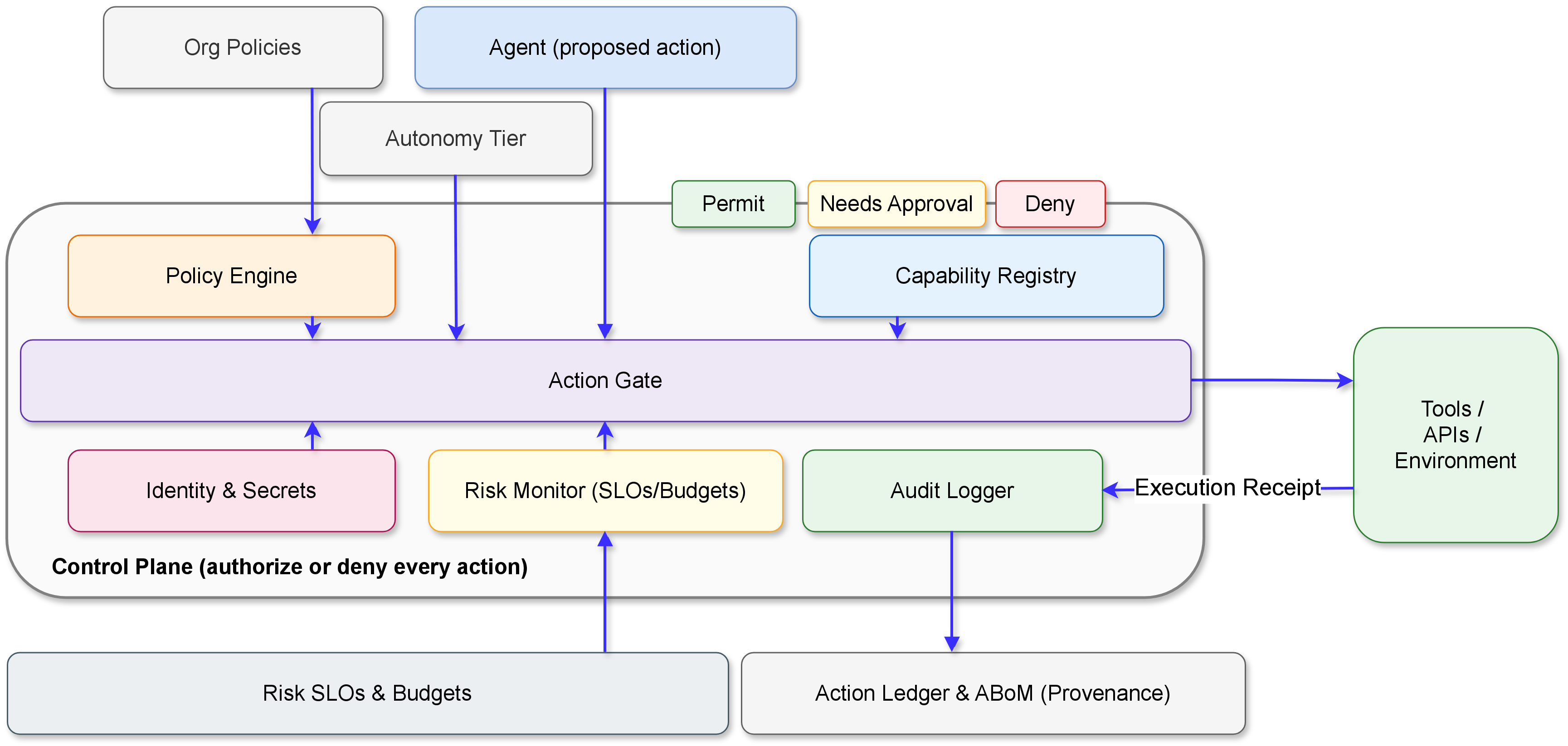
Regulatory Alignment
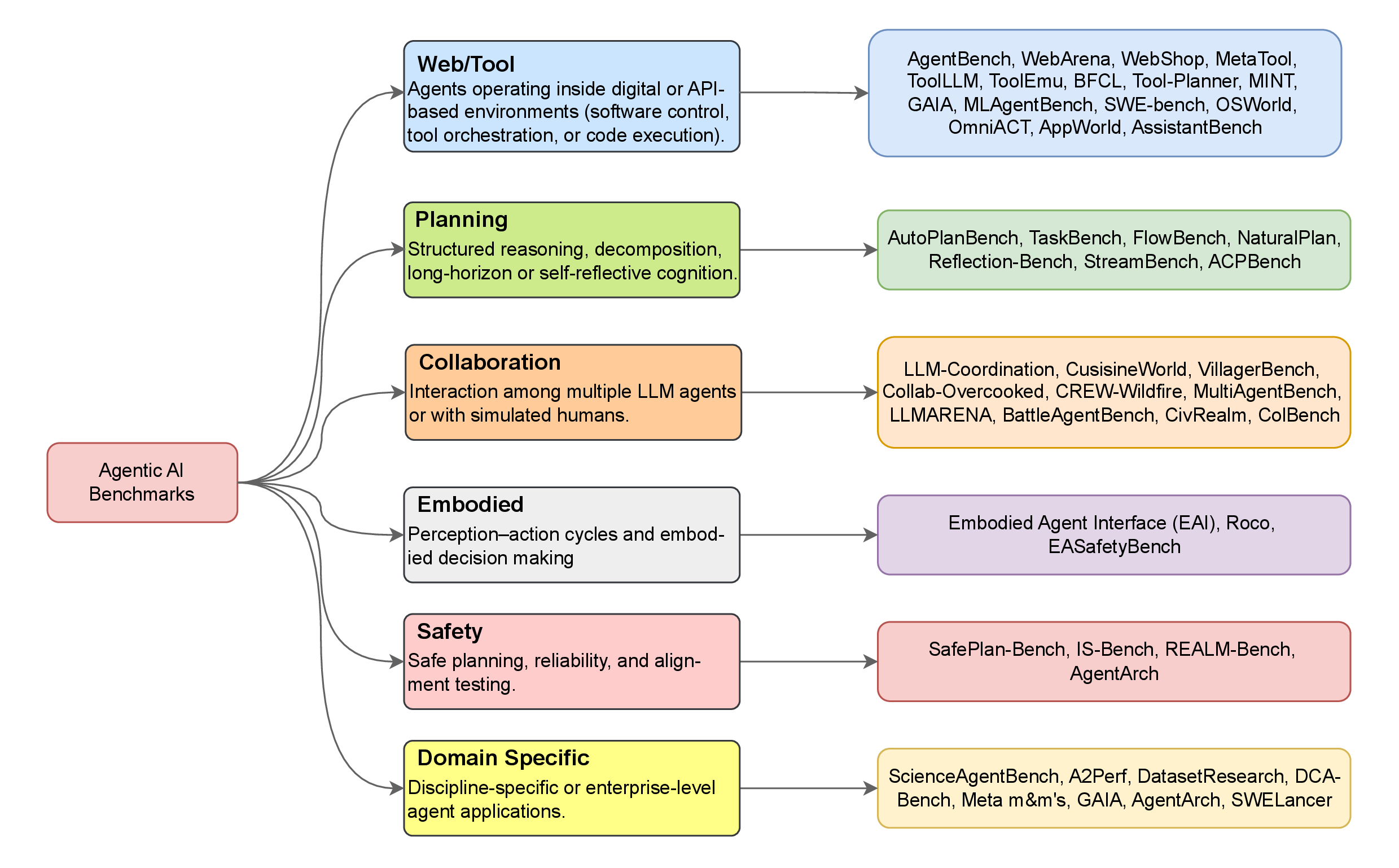
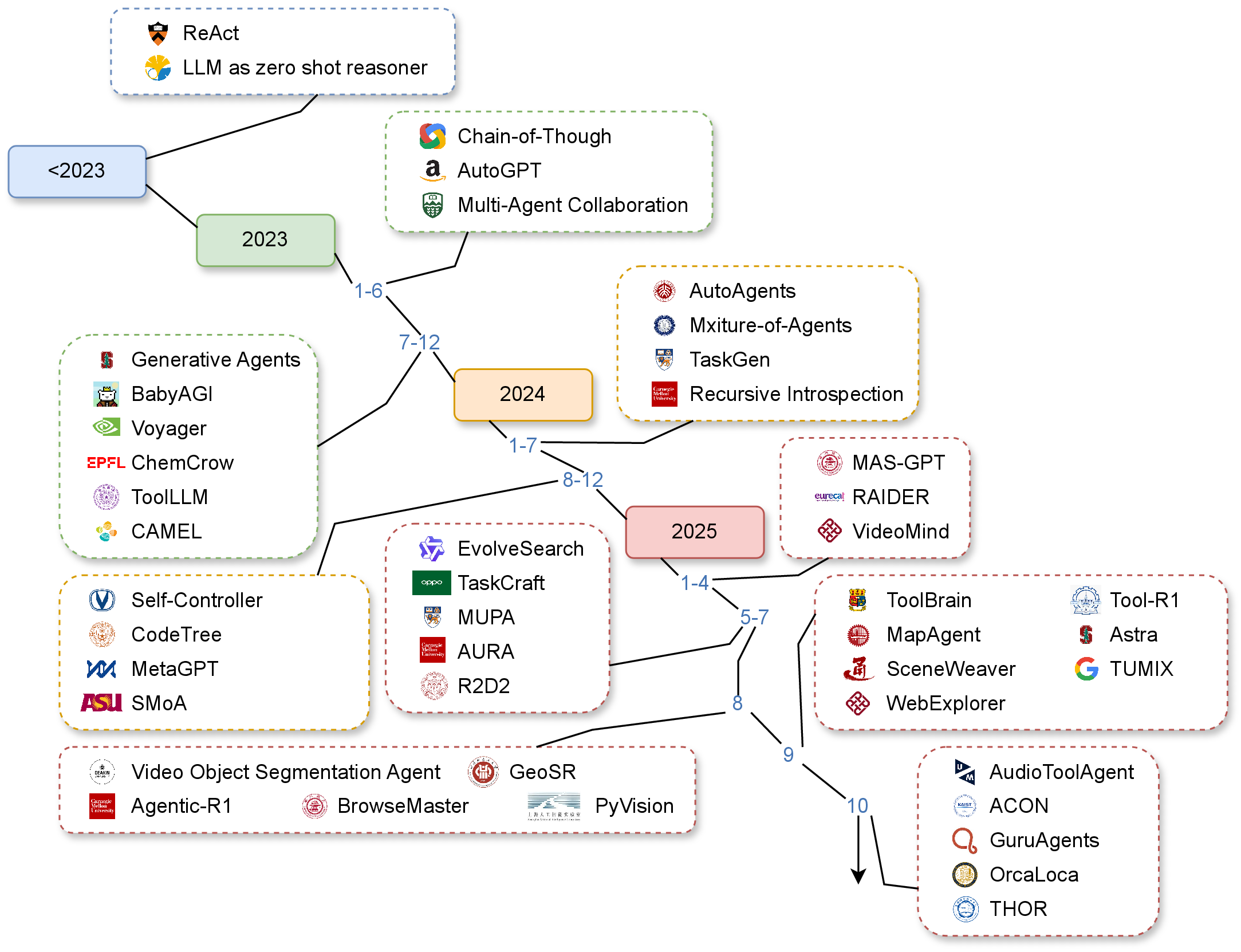
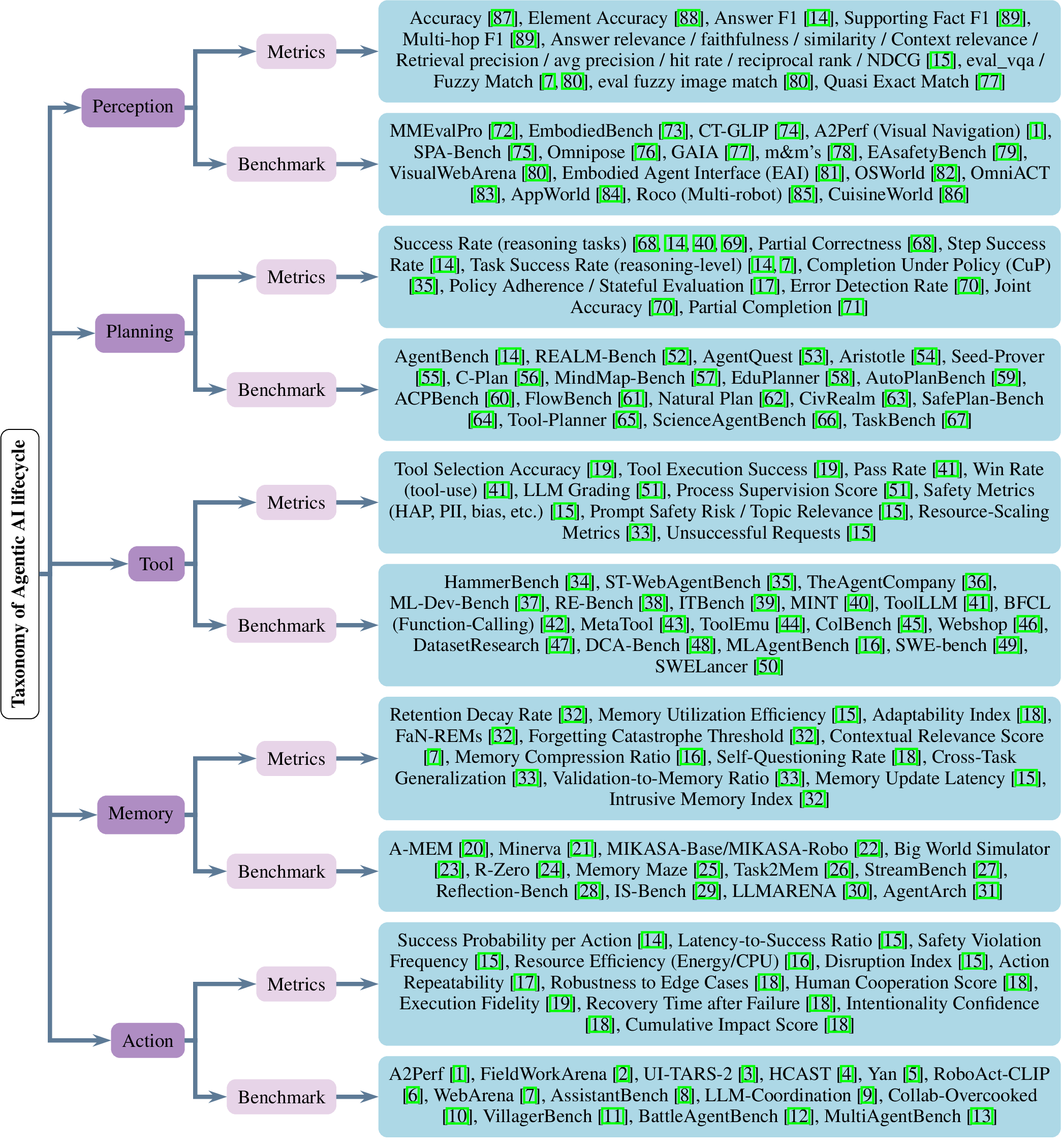
Agentic AI represents a new generation of Artificial Intelligence (AI) systems capable of perceiving, reasoning, planning, and acting toward achieving goals with a degree of autonomy. Unlike traditional AI models that merely generate outputs, these systems maintain memory, interact with their environment, and adapt over time. However, evaluating such interactive and evolving behavior remains a significant challenge. While several recent surveys have examined agentic AI architectures, components, and applications, few have systematically reviewed their evaluation, particularly regarding performance, reliability, and governance across an evolving agentic AI ecosystem. This paper addresses that gap by reviewing recent progress in the development and assessment of agentic AI, focusing on three core dimensions: benchmarks, metrics, and governance. We analyze how current evaluation frameworks capture reasoning, planning, collaboration, and ethical alignment across single- and multi-agent systems. Ultimately, this study aims to establish a unified foundation for building trustworthy, auditable, and human-aligned AI agents.
| Survey | Focus | Timeline | Benchmarks | Metrics | Governance |
|---|---|---|---|---|---|
| Yehudai et al. (2025) | Evaluation of LLM-based agents | Post | ✓ | ✓ | ◐ |
| Plaat et al. (2025) | Agentic LLMs: reason–act–interact | Post | ◐ | ◐ | ◐ |
| Acharya et al. (2025) | Agentic AI foundations & applications | Pre+Post | ◐ | ◐ | ✓ |
| Bandi et al. (2025) | Taxonomy: AI agents vs. agentic AI | Pre+Post | ✗ | ✗ | ◐ |
| Hughes et al. (2025) | Multi-expert industry analysis | Pre+Post | ✗ | ✗ | ✓ |
| Piccialli et al. (2025) | Distributed AgentAI for Industry 4.0 | Pre+Post | ◐ | ◐ | ✓ |
| Mohammadi et al. (2025) | Evaluation/benchmarking of LLM agents | Post | ✓ | ✓ | ✗ |
| Nisa et al. (2025) | Agentic AI overview (org transformation) | Pre+Post | ◐ | ◐ | ✗ |
| Yu et al. (2025) | Trustworthy & Security evaluation of agents | Post | ✗ | ◐ | ✗ |
| Ours | Benchmarks, metrics, and governance | Post | ✓ | ✓ | ✓ |
Legend: ✓ = Present / Strong, ◐ = Partial / Limited, ✗ = Absent, Pre = Pre-LLM era, Post = Post-LLM era.
@article{FAROOQ2026104444,
title = {Evaluating and regulating agentic AI: A study of benchmarks, metrics, and regulation},
journal = {Information Fusion},
volume = {136},
pages = {104444},
year = {2026},
issn = {1566-2535},
doi = {https://doi.org/10.1016/j.inffus.2026.104444},
url = {https://www.sciencedirect.com/science/article/pii/S1566253526003246},
author = {Azib Farooq and Shaina Raza and Nazmul Karim and Hasan Iqbal and Athanasios V. Vasilakos and Christos Emmanouilidis},
}